@DanT @kanedan29 Christophe
We (Our Sci) are quickly approaching a point where we’re getting asked for numbers (costs, prices, and net to farmer) from both ends (Nori, farmer groups, OpenTEAM partners, etc.).
I know there’s a lot of flexibility and unknowns, but we have enough experience there’s surprising number of knowns, and at least from a process perspective, I think we know how the stocking process would go (certainly Dan Kane knows!).
So I want to get the conversation started. I wrote this up to get things started here on the forum.
Goal of carbon stocking
Demand for carbon stocking for agricultural or land management applications are for tracking carbon for internal standards (companies with internal ag-related standards like General Mills, City of Boulder for internal GHG offsets within the city), for management decisions (grass fed beef for increasing soil C, regenerative ag transitions), and for carbon markets (row crop farmers w/ Nori or similar markets).
While all of these markets are real, the most significant increase in value to all those applications is connecting to a carbon market as it benefits all of them. We estimate that farms >100 acres would find it monetarily worth while to accumulate carbon credits, assuming a 1% change in carbon over 10 years and a local sample collection strategy involving multiple fields / farms.
As such, the primary design feature of carbon stocking measurements is to accurately track change over time on a single field.
We believe, based on discussions with Nori, estimates of expected carbon increase on typical row crop fields, and discussions with farmers directly, that a $2 - 3 cost per year for carbon stock estimation over a 10 year period (Christophe did I get this right? Edit plz or respond). This is the target any carbon stocking technology must hit to be successful.
Sampling Strategy Summary
Year 1: Collect samples, measure lab carbon (LOI) on all samples and Reflectance on all samples
→ build local model for predicting LOI from Reflectance.
middle years (years 3, 5, 7…): Collect samples, measure Reflectance only.
→ generate payouts based on increases in C.
Year 10: Collect samples, measure lab carbon (LOI) only.
→ final payout based on increase in C.
Modeling + selection
Background
Current modeling using Stratify and subsequent modeling software in R is effective at predicting carbon differences between ecosystems (soil types, texture class, and location). However, this isn’t the primary goal of carbon stocking - the goal is to capture change over time with predictable (and ideally high) confidence.
Spectroscopy (in field / or in lab using a reflectometer) is very effective at identifying change over time, but to do so requires a locally calibrated model (defining local as same physical field, same texture class, same soil type, etc.).
The core question is how to minimize cost / maximize accuracy of a local model with the goal of use in carbon markets.
Currently, Stratify is effective in specifying the highest impact sampling points within a region, relative to creating that local model. It takes into account:
- Soil Texture / Soil type
- Elevation
- Aspect (NSEW)
- Slope
- NDVI
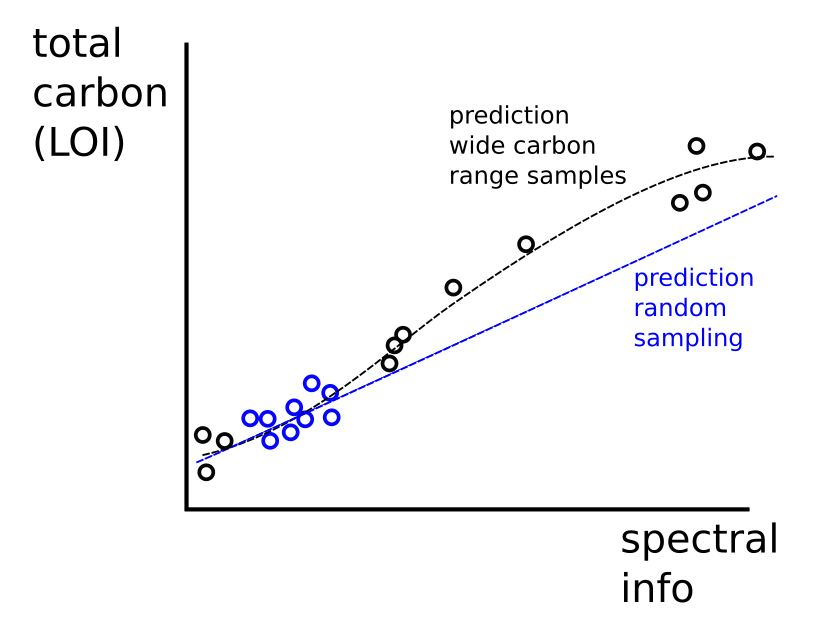
Within those ‘buckets’, samples are randomized. This is useful, but doesn’t maximize our ability to identify change over time because the model information is tight around a limited set of carbon values.
In short, expected future values will be outside of the training set because they will likely be higher. Also, in general, a more accurate model will be built with a wider range of similar carbon values (inside the buckets).
(IMO) One good way to handle this is to intentionally collect higher and lower carbon values than the standard field values. See below for an example graph showing random sampling (existing Stratify), as compared to sampling which intentionally selects high and low carbon values.
Recommended changes
Discussion with Jeff Herrick, Dan Kane, and internally (Dan T and Greg), there are few small changes that can be made to improve local models for change over time stocking estimates (increase accuracy / reduce sampling).
- Include hedgerows and areas near fields to support higher carbon value sampling within Stratify.
- Change Stratify to create buckets initially excluding NDVI (let’s call these ‘core buckets’). Show this mapping output to the user so they can see them. Then subset the ‘core buckets’ using NDVI (high to low) to more intentionally select both high and low carbon regions (assuming NDVI is a good proxy for carbon levels which I think it is).
- Also subset additional sampling at 10 - 20cm or 20 - 30cm within each ‘core bucket’ to pull more low carbon samples.
- If a ‘core bucket’ is likely to have minimal carbon range (there’s no high/low NDVI areas, etc.), the user should be informed and suggest to identify nearby locations that could support greater variability.
In addition, it’s important to add value to this process by stacking functions and packaging the offering in a way that farmers can do what makes most sense for them. It seems based on initial discussions, pH (for variable rate lime) and biological activity (for tracking regenerative ag changes) would have the most benefit to map alongside carbon, and are relatively low cost on a per sample basis.
Finally, allowing farmers to identify the depths (0 - 10, 10 - 20, 0 - 20, 20 - 30… dunno but something in there) to track may also be helpful as farms who need to occasionally till versus farms with perennial crops will likely maximize carbon benefit at different levels. This helps each farm maximize their benefit.
Cost estimation
See below cost estimate, but I think it gives a sense of where costs will be. There is a high cost and low cost version (more dense sampling, higher cost per sample, etc.) to get a sense of the variation.
None of the numbers are absolute, but @DanT and @kanedan29 you have enough experience to at least guess here and ballpark.
I created some tabs so you can play around with it. Feel free and see what you think.
What’s not in the sheet is…
- this requires someone who’s invested in soil sampling, has 4 wheelers, equipment and has enough farms in a given area that they can be efficient with their time. Need to work with agronomists and others locally to do this right.
- cost to generate maps and provide feedback to farmers / agronomists performing the work
- marketing + customer success
I was impressed that we are in the $0.5 - $2 per year per acre cost for carbon stock estimation with direct sampling. Feels achievable!
Please comment / edit / discuss below. I would love to start moving this conversation forward this winter, so we all feel confident (or not!) that this is an achievable method in carbon markets like Nori.